Last April, as Covid took hold, and as we were locked away in our homes, many took to baking. Instead I decided to re-implement Kubernetes. Those that gave me incredulous looks and suggested i’d gone of the rails - you were probably right. But the thing is, there was so much that frustrated me about it. I know technologies for building distributed, scalable, fault tolerant systems are intrinsically complex. But if there’s one thing i’ve learned in the last decade it’s that it’s important to distinguish between intrinsic and extrinsic complexity.
Extrinsic complexity is created from at least two causes. Firstly, imperfect decisions are made in an implementation caused by inevitably not fully understanding a problem until you’ve implemented a solution to it. Secondly, juggling technical debt on a project where there are many unknowns. In this situation much of the work is in building scaffolding to support research into the right direction. Often this scaffold becomes hard to remove once the “wood” has grown around it.

Tree has grown through the railings
Mistakes
So why did I think I could do better? Firstly, my background in resource oriented computing has given me a very different perspective on the world than most, and secondly, hopefully I can learn from Kubernetes mistakes. Maybe mistakes is too strong a word, but these are the mistakes I think Kubernetes has made:
Resource Requirements are too high - It is just about possible to run a Kubernetes cluster for development on a high-end laptop, it is much better to provision a set of moderately configured cloud servers and run it there. As I research this now, I see there are guides to setting up Kubernetes on a Raspberry Pi cluster. I hope that suggests signs of optimization, but I know the underlying design decisions have not changed. The problem is that Kubernetes consists of many discrete services and processes each with their own dependencies and software stacks below. Which leads into the next mistake:
Setup and Configuration takes an expert - The usual approach to setting up a Kubernetes cluster is to use a wizard from a cloud provider, or some distribution or product. This wizard hides much of the complexity of setup which is of course good until something goes wrong, or you need to tune, or do something non-standard - which is usually most of the time! Public Key encryption Infrastructure (PKI) is really hard to setup too but necessary for a secure deployment. Of course all this knowledge can be acquired and you can invest in becoming an expert in Kubernetes, in fact many are specializing in exactly this.
Steep Learning Curve - When the depth of knowledge needed to correctly use Kubernetes is that high it doesn’t scale - scale downwards that is. It limits Kubernetes use to being on cloud providers who deal with it, or to large projects that can support the overhead of an expert. Many people and systems that require a compute cluster just want fault tolerance and scaling without all the hassle and time involved.
Inversion of the Discovery Model - This isn’t so much of fault of Kubernetes as an decision I wanted to challenge. From the perspective of cloud providers and running in a cloud environment, the ease of spinning up and down instances makes it logical to allow kubernetes to directly specify the compute resources needed. But from a hobbyist, or organisation with on-premise servers, it makes sense to have a provisioned set of machines ready to join clusters and accept work.
Ok, so Kubernetes has also done a lot of stuff right. I wanted it’s core functionality of:
- Scaling - ability to run a service on multiple machines and share load across them.
- Fault tolerance - ability to detect failures of machines, remove them from the cluster and reroute work.
- Metrics and telemetry - capture operation and functional metrics about the cluster as a whole, as well as each pod.
- Rollout functionality - ability to specify versioned functionality and roll out onto cluster
Sqwish
It’s called Sqwish because I wanted to take all the goodness of kubernetes and squish it into something small, cute, and easy to play with. It’s built in NetKernel so I already had a solid foundation for dynamically deploying functionality and robust and secure networked services.
One bugbear i have with many open source projects is that they don’t state their design(ed) limitations. So i’ll be explicit; these are Sqwishes limitations:
- Single point of failure - I deliberately didn’t try and solve this problem as it makes everything else 10x harder. If my proof of concept proved worthwhile it is a no-risk solvable problem just a lot of work.
- In memory metrics - Integrating a database and better management of the captured data didn’t seem like a hard problem or risk so I just used a quick in memory structure for keeping a window of data.
- NetKernel - because Sqwish is built on NetKernel it can only deploy NetKernel modules. In addition clients connecting the cluster must also be NetKernel modules.
Features
Architecture - The single cluster manager has a TLS socket connection that all clients and agents must connect to to join the cluster. Clients can send requests into the cluster. Agents can receive and process requests dependent upon which replicaSets they host. ReplicaSets are sets of NetKernel modules. Any modules in a replicaSet that declare a dynamic import hook to the Sqwish Agent Fulcrum will be exposed as endpoints for that replicaSet and clients will be able to issue requests to them via the cluster manager.
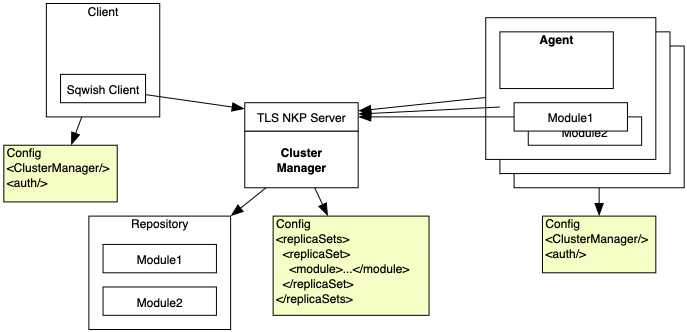
Figure 1: Sqwish block diagram of architecture
Dynamic discovery of endpoints - One of the cool things about NetKernel is that metadata about endpoints is shared on the network protocol. Because of this, when modules are deployed on the cluster the cluster manager can track each worker nodes status and the performance of each endpoint within each node.
Dynamic updates and deployment of functionality - New modules can be deployed across the cluster by updating the configuration on the cluster manager. It will not route requests to an agent until the update has occured and the agent can demonstrate the new modules are deployed.
Telemetry - agents send periodic updates to the cluster manager with all their pertinent operating statistics. This doubles as a keep-alive ping. If for any reason an agent appears to be non-functional it is removed from the cluster until it can report a healthy status.
Rate adaption and queuing - the cluster manager will rate limit requests to agents based upon their capacity - at the moment just limiting concurrency to the CPU core count. If ingress from clients exceeds egress to agents the cluster manager will queue requests.
Simple security - Each client and agent must negotiate a secure TLS connection to the cluster manager. Each connection must then authenticate itself to the cluster manager using a username/password pair. Once the connection is established each party can communicate asynchronously to the cluster manager and vice versa.
Dashboard - the dashboard shows execution statistics and telemetry from each agent.
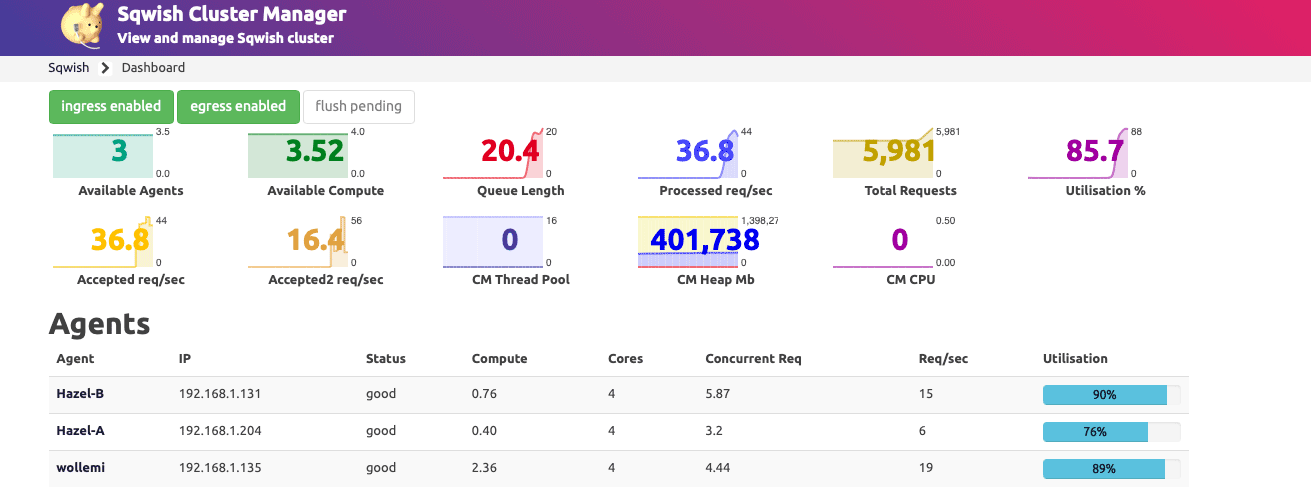
Figure 2: Sqwish Dashboard
Development setup
For development I ran the cluster manager on a laptop and had 3 agents running on Raspberry Pis connected via a wired network.

Figure 3: The Servers - 3 Raspberry Pis
Conclusion
This was an interesting project but ultimately, for the moment at least, i decided not to pursue it further. It did achieved my aims of being simple to configure, have a small code base, and to be low on resources. On that basis I consider it to be a successful experiment.
The repository for this project along with some tests to simulate load are available on GitLab and is MIT Licenced.